强化学习已经在各个领域大放光彩,游戏、机器人,在LLM领域更是后训练的强力手段。所以,有必要添加进个人技能库。
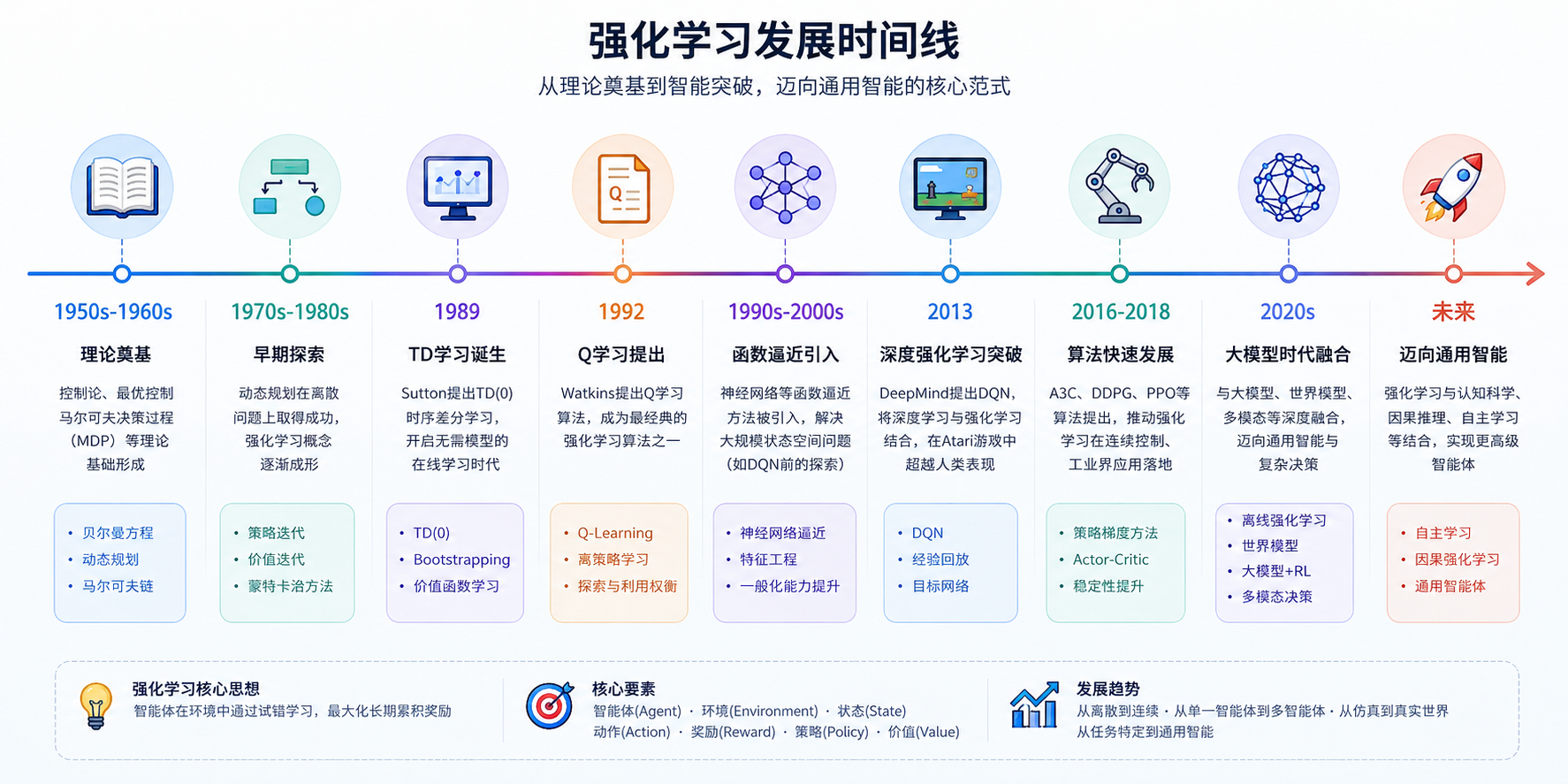
强化学习发展
上图展示了RL的发展时间线,早在上世纪五六十年代,其理论就已经出现,不得不说,真是天才。不过真正让强化学习进入大众视野的应该是在2016年3月,DeepMind开发的AlphaGo程序利用强化学习算法以4:1击败世界围棋高手李世石(那会我还在上初中🥹)。
前言
强化学习涉及到几个重要概念,Agent、Action、State、Reward、Environment。
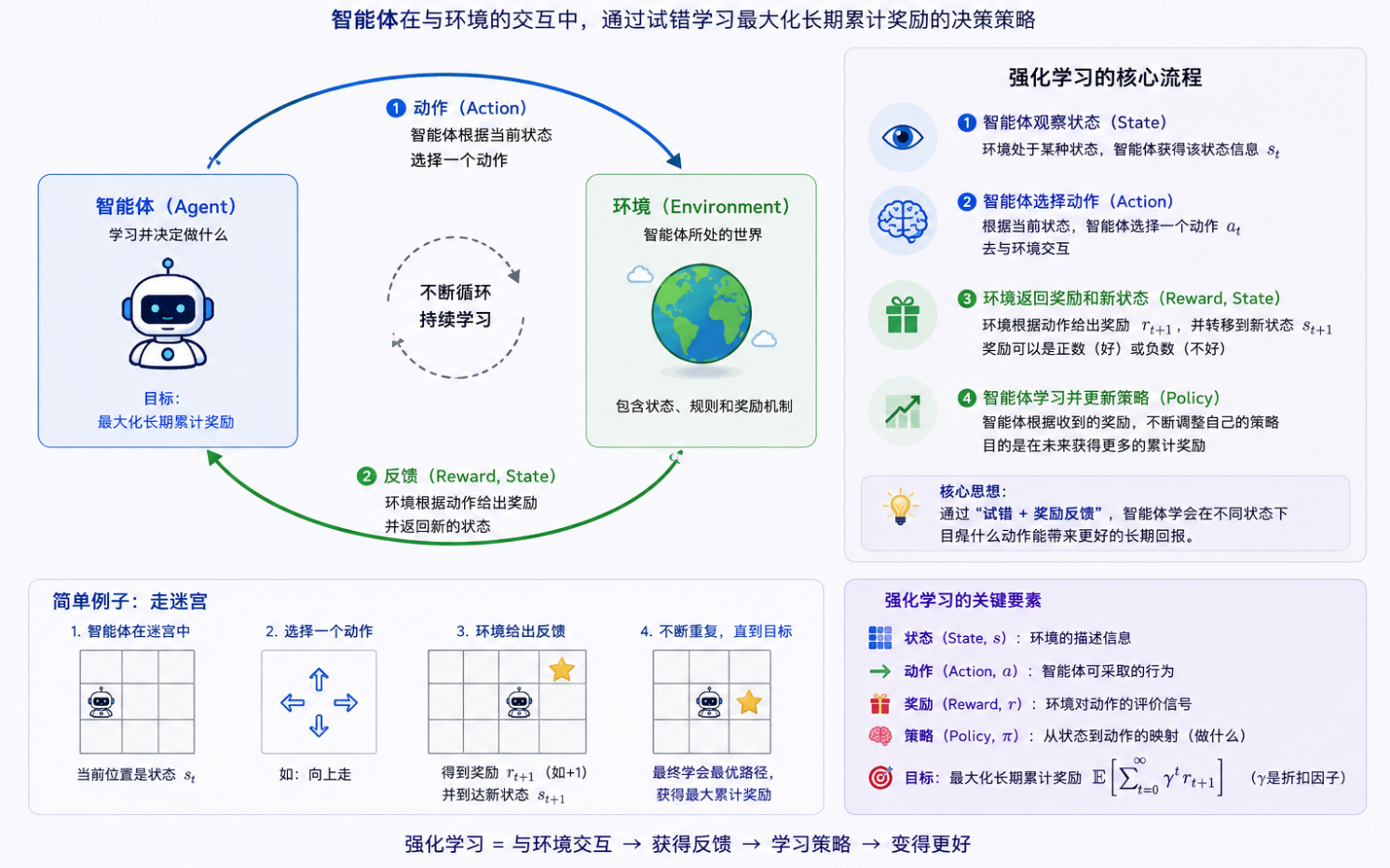
强化学习原理
上图解释了强化学习的基本原理。Agent在完成某项任务时,首先通过动作Action与周围环境Environment进行交互,在两者作用下,智能体会产生新的状态(State),同时环境会给出一个立即回报(Reward),如此循环下去,Agent与环境进行不断交互从而产生很多数据。强化学习算法利用产生的数据修改自身的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善自身行为,经过数次迭代学习后,Agent最终能学习到完成相应任务的最优动作(策略)。
从原理可以看出RL与其他机器学习算法比如监督学习和非监督学习的一些区别。在SFT和UL中,数据是静态的,不需要和环境交互,比如图像识别,只要给足够差异样本,将数据输入到深度神经网络中进行训练即可。而强化学习的过程是动态的,不断交互的过程,所需要的数据也是通过与环境不断交互产生。所以,与SFT和UL相比,RL涉及到的对象更多,比如动作、环境、状态转移概率和奖励函数等。RL更像是人类学习的过程。另外,深度学习如图像识别和语音识别解决的是感知的问题,强化学习解决的是决策的问题。人工智能的终极目的是通过感知进行智能决策。所以,将近年发展起来的深度学习技术与强化学习算法结合而产生的深度强化学习算法是人类实现人工智能终极目的的一个很有前景的方法。
一些学者探索出一套可以解决大部分强化学习问题的框架 —— 马尔科夫决策过程,简称MDP。
马尔科夫过程
随机过程
随机过程(stochastic process)是概率论的“动力学”部分。概率论的研究对象是静态的随机现象,而随机过程的研究对象是随时间演变的随机现象(比如天气随时间的变化、城市交通随时间的变化)。在随机过程中,随机现象在某时刻 的取值是一个随机变量,用 表示,所有可能的状态组成状态集合 。随机现象便是状态的变化过程。在某时刻 的状态 通常取决于 时刻之前的状态。我们将已知历史信息 时下一个时刻状态 的概率表示成 。
马尔科夫性质
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质(Markov property),用公式表示为 。也就是说,当前状态是未来的充分统计量,即下一个状态只取决于当前状态,而不会受到过去状态的影响。需要明确的是,具有马尔可夫性并不代表这个随机过程就和历史完全没有关系。因为虽然 时刻的状态只与 时刻的状态有关,但是 时刻的状态其实包含了 时刻的状态的信息,通过这种链式的关系,历史的信息被传递到了现在。马尔可夫性可以大大简化运算,因为只要当前状态可知,所有的历史信息都不再需要了,利用当前状态信息就可以决定未来。
马尔科夫过程(Markov process)
马尔可夫过程指具有马尔可夫性质的随机过程,也被称为 马尔可夫链(Markov chain)。我们通常用元组 描述一个马尔可夫过程,其中 是有限数量的状态集合,$P$ 是状态转移矩阵(state transition matrix)。假设一共有 个状态,此时 。状态转移矩阵 定义了所有状态对之间的转移概率,即
矩阵 中第 行第 列元素 表示从状态 转移到状态 的概率,我们称 为状态转移函数。从某个状态出发,到达其他状态的概率和必须为 1,即状态转移矩阵 的每一行的和为 1。
下图是一个具有 6 个状态的马尔可夫过程的简单例子。其中每个绿色圆圈表示一个状态,每个状态都有一定概率(包括概率为 0)转移到其他状态,其中 通常被称为 终止状态(terminal state),因为它不会再转移到其他状态,可以理解为它永远以概率 1 转移到自己。状态之间的虚线箭头表示状态的转移,箭头旁的数字表示该状态转移发生的概率。从每个状态出发转移到其他状态的概率总和为 1。例如,$s1$ 有 90% 概率保持不变,有 10% 概率转移到 $s2$,而在 又有 50% 概率回到 ,有 50% 概率转移到 。
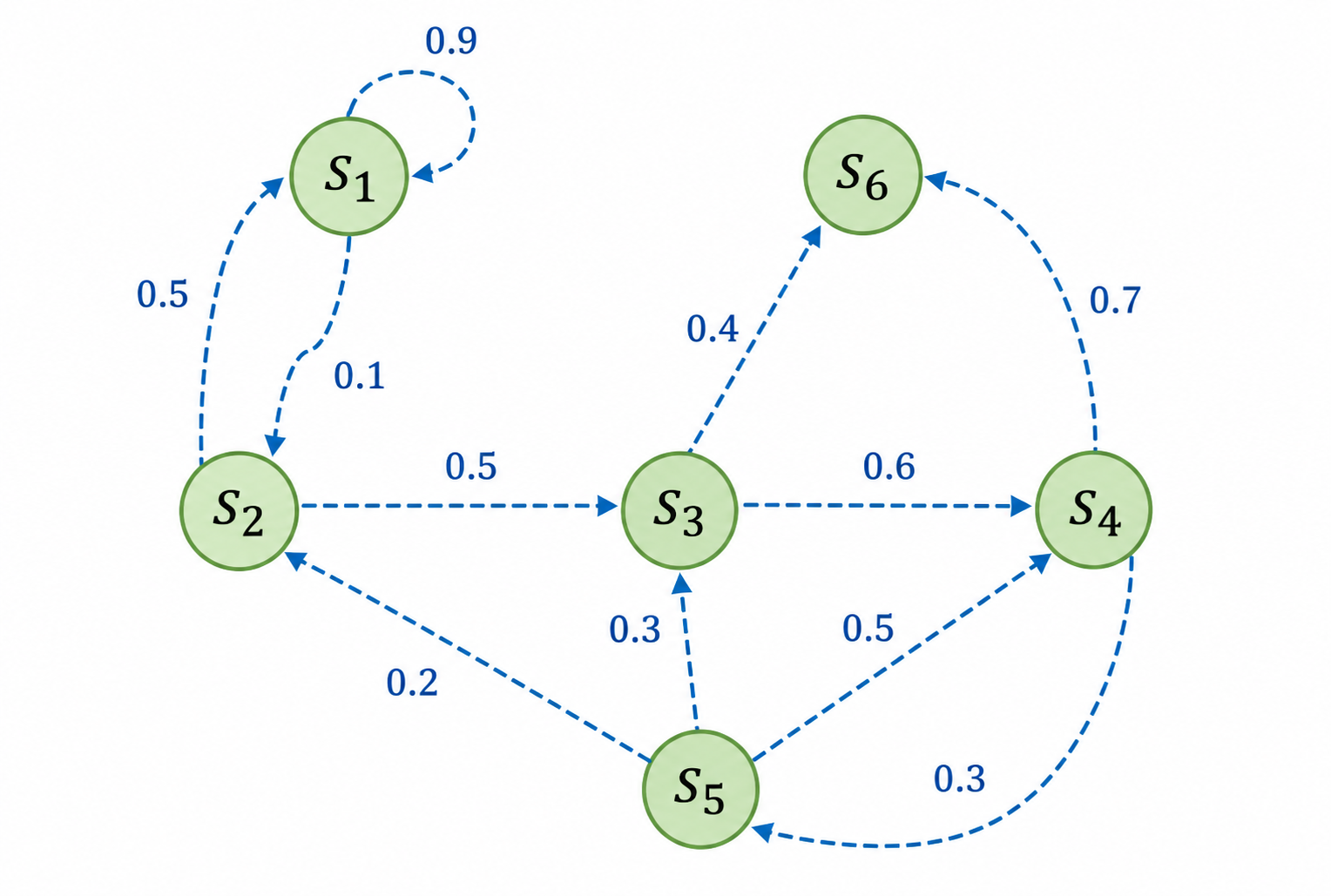
我们可以写出这个马尔可夫过程的状态转移矩阵:
其中第 行第 列的值 则代表从状态 转移到 的概率。
给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列(episode),这个步骤也被叫做采样(sampling)。例如,从 出发,可以生成序列 或序列 等。生成这些序列的概率和状态转移矩阵有关。
马尔科夫奖励过程
在马尔可夫过程的基础上加入奖励函数 和折扣因子 ,就可以得到 马尔可夫奖励过程(Markov reward process)。一个马尔可夫奖励过程由 构成,各个组成元素的含义如下所示。
- 是有限状态的集合。
- 是状态转移矩阵。
- 是奖励函数,某个状态 的奖励 指转移到该状态时可以获得奖励的期望。
- 是折扣因子(discount factor),$\gamma$ 的取值范围为 。引入折扣因子的理由为远期利益具有一定不确定性,有时我们更希望能够尽快获得一些奖励,所以我们需要对远期利益打一些折扣。接近 的 更关注长期的累计奖励,接近 的 更考虑短期奖励。
回报
在一个马尔可夫奖励过程中,从第 时刻状态 开始,直到终止状态时,所有奖励的衰减之和称为 回报 (Return),公式如下:
其中,$Rt$ 表示在时刻 获得的奖励。在下图中,继续沿用马尔可夫过程的例子,并在其基础上添加奖励函数,构建成一个马尔可夫奖励过程。例如,进入状态 $s2$ 可以得到奖励 ,表明我们不希望进入 ,进入 可以获得最高的奖励 ,但是进入 之后奖励为零,并且此时序列也终止了。
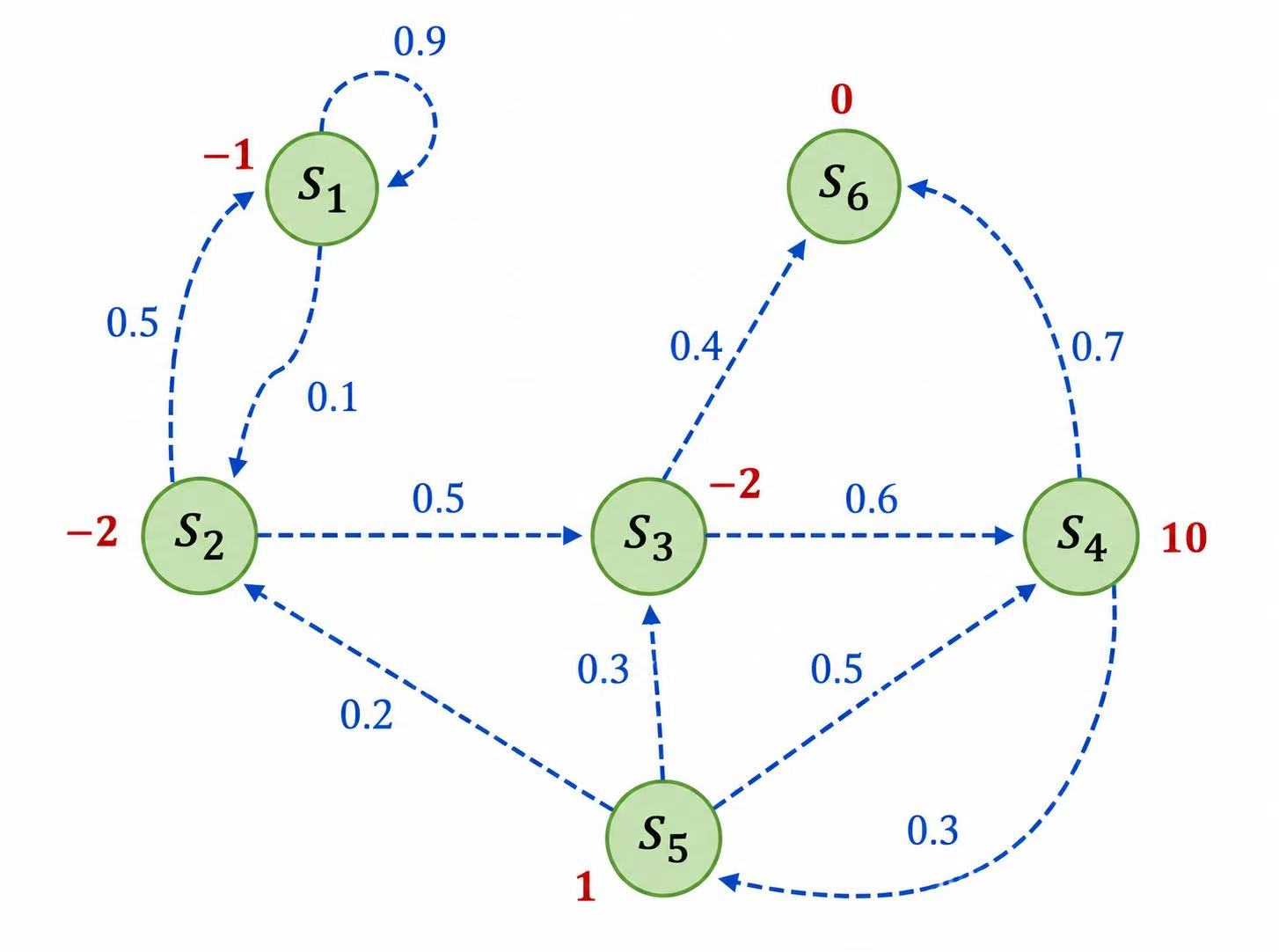
比如选取 为起始状态,设置 ,采样到一条状态序列为 ,就可以计算 的回报 ,得到
价值函数
在马尔可夫奖励过程中,一个状态的期望回报(即从这个状态出发的未来累积奖励的期望)被称为这个状态的价值(value)。所有状态的价值就组成了价值函数(value function),价值函数的输入为某个状态,输出为这个状态的价值。我们将价值函数写成 ,展开为
在上式的最后一个等号中,一方面,即时奖励的期望正是奖励函数的输出,即 ;另一方面,等式中剩余部分 可以根据从状态 出发的转移概率得到,即可以得到
上式就是马尔可夫奖励过程中非常有名的 贝尔曼方程(Bellman equation),对每一个状态都成立。
若一个马尔可夫奖励过程一共有 个状态,即 ,我们将所有状态的价值表示成一个列向量 ,同理,将奖励函数写成一个列向量
。于是我们可以将贝尔曼方程写成矩阵的形式:
我们可以直接根据矩阵运算求解,得到以下解析解:
马尔科夫决策过程
前面讨论到的马尔可夫过程和马尔可夫奖励过程都是自发改变的随机过程;而如果有一个外界的“刺激”来共同改变这个随机过程,就有了 马尔可夫决策过程(Markov decision process, MDP)。我们将这个来自外界的刺激称为 智能体(agent)的动作,在马尔可夫奖励过程(MRP)的基础上加入动作,就得到了马尔可夫决策过程(MDP)。马尔可夫决策过程由元组 构成,其中:
- 是状态的集合;
- 是动作的集合;
- 是折扣因子;
- 是奖励函数,此时奖励可以同时取决于状态 和动作 ,在奖励函数只取决于状态 时,则退化为 ;
- 是状态转移函数,表示在状态 执行动作 之后到达状态 的概率。
马尔科夫决策过程是一个与时间相关的不断进行的过程,在智能体与环境 MDP 之间存在一个不断交互的过程。一般而言,智能体根据当前状态 选择动作 ;对于状态 和动作 ,MDP 根据奖励函数和状态转移函数得到 和 并反馈给智能体,智能体的目标是最嗲话得到的累计奖励。智能体根据当前状态从动作的集合 中选择一个动作的函数,被称为策略。

策略
智能体的策略(Policy)通常用字母 表示。策略 是一个函数,表示在输入状态 情况下采取动作 的概率。当一个策略是确定性策略(deterministic policy)时,它在每个状态时只输出一个确定性的动作,即只有该动作的概率为 ,其他动作的概率为 ;当一个策略是随机性策略(stochastic policy)时,它在每个状态时输出的关于动作的概率分布,然后根据该分布进行采样就可以得到一个动作。在MDP中,由于马尔可夫性质的存在,策略只需要与当前状态有关,不需要考虑历史状态。回顾一下在MRP中的价值函数,在MDP中也同样可以定义类似的价值函数。但此时的价值函数与策略有关,这意为着对于两个不同的策略来说,它们在同一个状态下的价值也很可能是不同的。这很好理解,因为不同的策略会采取不同的动作,从而之后会遇到不同的状态,以及获得不同的奖励,所以它们的累积奖励的期望也就不同,即状态价值不同。
状态价值函数
我们用 表示在 MDP 中基于策略 的状态价值函数(state-value function),定义为从状态 出发遵循策略 能获得的期望回报,数学表达为:
动作价值函数
不同于 MRP,在 MDP 中,由于动作的存在,我们额外定义一个 动作价值函数(action-value function)。我们用 表示在 MDP 遵循策略 时,对当前状态 执行动作 得到的期望回报:
状态价值函数和动作价值函数之间的关系:在使用策略 中,状态 的价值等于在该状态下基于策略 采取所有动作的概率与相应的价值相乘再求和的结果:
使用策略 时,状态 下采取动作 的价值等于即时奖励加上经过衰减后的所有可能的下一个状态的状态转移概率与相应的价值的乘积: