Function Calling
ok啊,直接步入正题,先来了解下什么是Function Calling
Function Calling由OpenAI等公司推动,允许大语言模型与外部工具连接,将自然语言转换为API 调用。这解决了大模型在训练结束,就知识更新停滞的问题。
通俗解释就是:
大语言模型(像 ChatGPT)本身学到的知识是在训练时固定的,训练完它就不会自动“长新知识”但是,通过 Function Calling 这个机制,我们可以让模型在对话时,直接调用外部工具或接口(比如天气API、股票查询 API、数据库等),实时获取最新信息,并把结果再返回给你。 就像:
- 模型原来是一本“印刷好的书”,印好之后就不能改。
- 现在给它配了一部“智能手机”,它可以在回答问题前,先去上网查、问工具拿数据,再告诉你最新的答案
这样,它不仅能理解你的话,还能动手去查或做事,而不是只靠旧记忆说话。
工作原理
Function Calling原理并不复杂,通过代码进行说明
OpenAI的api需要收费,也比较麻烦,所以这里用智谱来演示,效果一样
from zhipuai import ZhipuAI
from env_config import ZHIPU_API_KEY
# 初始化zhipuai客户端
client = ZhipuAI(api_key=ZHIPU_API_KEY)
# 定义工具参数
tools = [{
'type': 'web_search', # 网页搜索
'web_search': {
'enable': True,
'search_engine': 'search_pro_sogou', # 搜索引擎类型
'search_result': True,
'search_prompt': '你是一名财经分析师,请用简洁的语言总结网络搜索结果中:{{search_result}}中的关键信息,按重要性排序并标注来源日期'
}
}]
# 定义用户消息
messages = [{
'role': 'user',
'content': '2025年7月份重要财经事件、政策变化和市场数据'
}]
# 调用API获取响应
response = client.chat.completions.create(
model='glm-4-air-250414', # 模型编码
messages=messages,
tools=tools
)
# print(response) # response是一个Completion对象,我们需要拿到它的choices
for choice in response.choices:
print(choice.message.content)
输出如下:
以下是2025年7月份的重要财经事件、政策变化和市场数据,按重要性排序并标注来源日期:
### 1. **中国7月国民经济保持稳中有进发展态势**
- **内容**:工业生产较快增长(规模以上工业增加值同比增长5.7%),装备制造业和高技术制造业增长显著(分别增长8.4%和9.3%)。服务业商务活动指数为50.0%,市场销售继续增长(社会消费品零售总额同比增长3.7%)。
- **来源**:[ref_6](7月新闻发布会)、[ref_7](国家统计局答记者问)、[ref_9](经济数据总结)。
### 2. **中国金融数据:M2增长8.8%,贷款投放稳健**
- **内容**:7月末广义货币(M2)余额329.94万亿元,同比增长8.8%;前七个月人民币贷款增加12.87万亿元,存款增加18.44万亿元。
- **来源**:[ref_5](金融统计数据报告)。
......
可以看到,这些信息并不能及时作为语料给大模型训练,但是可以通过Function Call的方式调用外部接口拿到最新的数据,这就是Function Call强大之处。
ZhipuAI+Agent
再通过一个智能体案例引出agent
这里想说一句,langchain版本更新后,包的位置都变了,函数也做了修改,调试起环境还是有点脑壳痛
from langchain_openai import ChatOpenAI
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from zhipuai import ZhipuAI
from env_config import ZHIPU_API_KEY
# 创建客户端
zhipuai_client = ZhipuAI(api_key=ZHIPU_API_KEY)
llm = ChatOpenAI( # zhipuai的
temperature=0,
model='glm-4-air-250414',
api_key=ZHIPU_API_KEY,
base_url="https://open.bigmodel.cn/api/paas/v4/")
# 定义搜索输入的模型
class SearchInput(BaseModel):
query: str = Field(description='需要搜索的内容或者关键词')
# 定义搜索工具函数
@tool('my_search_tool', args_schema=SearchInput)
def my_search(query: str) -> str:
"""搜索互联网上的内容"""
try:
# 调用客户端进行网络搜索
response = zhipuai_client.web_search.web_search(
search_engine="search-std",
search_query=query
)
# 打印搜索结果
# print("搜索内容:", response)
# 如果搜索结果存在,返回结果内容
if response.search_result:
return "\n\n".join([d.content for d in response.search_result])
except Exception as e:
# 打印异常信息
print(e)
# 返回没有搜索到任何内容的提示
return '没有搜索到任何内容!'
# 定义聊天提示模板
prompt = ChatPromptTemplate.from_messages([
('system', '你是一个智能助手,尽可能的调用工具回答用户的问题'),
# 占位符用于存储聊天历史
MessagesPlaceholder(variable_name='chat_history', optional=True),
('human', '{input}'),
# 占位符用于存储代理的临时信息
MessagesPlaceholder(variable_name='agent_scratchpad', optional=True),
])
# 定义工具列表
tools = [my_search]
# 创建智能体
agent = create_tool_calling_agent(llm, tools=tools, prompt=prompt)
# 创建智能体执行器
executor = AgentExecutor(agent=agent, tools=[my_search])
# 定义存储会话历史的字典
store = {}
# 获取会话历史的方法
def get_session_history(session_id: str) -> BaseChatMessageHistory:
# 如果会话ID不在存储字典中,创建一个新聊天历史记录
if session_id not in store:
store[session_id] = ChatMessageHistory()
# 返回会话历史记录
return store[session_id]
# 创建带有会话历史的智能体
agent_with_history = RunnableWithMessageHistory(
executor,
get_session_history,
input_messages_key='input',
history_messages_key='chat_history'
)
# 调用代理处理用户输入
resp1 = agent_with_history.invoke(
{'input': '你好, 我是扳布,出生在2002年'},
config={'configurable': {'session_id': 'bamboo'}}
)
# 打印代理的响应
print("回答1:", resp1['output'])
# 调用智能体处理用户输入
resp2 = agent_with_history.invoke(
{'input': '我出生的那一年,国际上发生哪些大事'},
config={'configurable': {'session_id': 'bamboo'}}
)
# 打印代理的响应
print("回答2:", resp2["output"])
输出如下:
回答1: 你好,扳布!很高兴认识你。请问有什么我可以帮助你的吗?
回答2: 2002年,国际上发生了一些重要的大事,包括:
1. **伊拉克武器核查问题**:联合国与伊拉克达成一致,允许武器核查人员重返巴格达。
2. **诺贝尔奖揭晓**:2002年诺贝尔奖在多个领域颁发,包括生理学或医学奖、物理学奖、经济学奖、化学奖、和平奖和文学奖。
3. **印尼巴厘岛爆炸事件**:印度尼西亚旅游胜地巴厘岛发生针对外国人的系列爆炸事件,造成近190人死亡,320多人受伤。
......
这些事件对国际政治、经济和文化产生了深远的影响。如果你对其中某个事件有更详细的兴趣,我可以提供更多信息。
重点分析
上面代码有几个关键点需要进行说明:
prompt = ChatPromptTemplate.from_messages([
('system', '你是一个智能助手,尽可能的调用工具回答用户的问题'),
# 占位符用于存储聊天历史
MessagesPlaceholder(variable_name='chat_history', optional=True),
('human', '{input}'),
# 占位符用于存储代理的临时信息
MessagesPlaceholder(variable_name='agent_scratchpad', optional=True),
])
系统提示:告诉 Agent 要尽量调用工具来回答问题。
MessagesPlaceholderchat_history:用来加载历史对话(记忆)agent_scratchpad:用来记录 Agent 中间推理过程(ReAct 格式)
{input}:替换为用户输入
agent_scratchpad
这里需要重点讲一下agent_scratchpad
- 直译就是“智能体的草稿本”
- 它是 在 Agent 推理过程中用来记录中间思考步骤的一个地方。
- 这个“中间步骤”对用户不可见(除非你把它打印出来),它是给 Agent 自己用的。在 LangChain、Llamalndex等Agent 框架中,agent scratchpad 往往就是一个字符串变量,里面存放了:
- Agent 之前调用工具的记录
- 工具返回的结果
- Agent 的思考笔记(reasoning)
为什么要记录中间推理过程
想象你在解决一个问题
- 先想一想需要什么信息
- 去查资料(调用工具)
- 得到资料后再思考下一步
- 直到得出最终答案
如果没有“草稿本”,Agent 每次都得从零推理,不记得自己之前做过什么。有了 agent_scratchpad,Agent 就像有了一个白板,可以写下
- “我上一步调用了 XXX 工具”
- “工具返回了 YYY 数据“
- ”下一步我应该......“
ReAct格式
ReAct = Reasoning + Acting(推理+行动)
它是一种大模型 Agent 推理模式,步骤通常是这样:
Thought: 我需要先查一下北京的天气。
Action: get_weather{"city": "北京"}
Observation: {"weather":"晴","temp":12}
Thought: 已经拿到天气信息,可以回答用户了。
Final Answer: 北京今天晴,温度是12°C。
- Thought →推理过程(写给自己看的)
- Action → 调用工具
- Observation →工具返回结果
- Final Answer→最终给用户的答案
agent_scratchpad和ReAct关系
agent scratchpad就是存 Thought/Action/Observation 这些中间记录的地方Agent 在下一步思考时,会把
agent scratchpad里的内容作为上下文传给大模型,让它知道之前做过什么,从而决定下一步要做什么。
总结一句话:
agent_scratchpad 是 Agent 的推理笔记本,用 ReAct 格式记录中间的思考、工具调用和结果,帮助 Agent 在多步推理中记住自己之前做了什么。
Agent
什么是AI Agent
将Agent视为人工智能大脑,它使用LLM进行推理、计划和采取行动。
AI Agent 被认为是 OpenAI 发力的下一个方向。OpenAI 联合创始人 Andrej Karpathy 在近期的公开活动上说 “ 相比模型训练方法,OpenAI 内部目前更关注 Agent 领域的变化,每当有新的 AI Agents 论文出来的时候,内部都会很兴奋并且认真地讨论 ” 。
在人工智能领域,这一术语被赋予了一层新的含义:具有自主性、反应性、积极性和社交能力特征的智能实体。
AI Agent,它被设计为具有独立思考和行动能力的AI程序。你只需要提供一个目标,比如写一个游戏、开发一个网页,他就会根据环境的反应和独白的形式生成一个任务序列开始工作。就好像是人工智能可以自我提示反馈,不断发展和适应,以尽可能最好的方式来实现你给出的目标。
NLP 到 AGI 的发展路线分为五级:语料库、互联网、感知、具身和社会属性,那么目前的大型语言模型已经来到了第二级,具有互联网规模的文本输入和输出。在这个基础上,如果赋予 LLM-based Agents 感知空间和行动空间,它们将达到第三、第四级。进一步地,多个代理通过互动、合作解决更复杂的任务,或者反映出现实世界的社会行为,则有潜力来到第五级 —— 代理社会。
为什么需要Agent
这个问题其实和function call出现的原因类似,文章开头就给出了答案,这里给出几点补充
LLM缺点:
- 会产生幻觉。
- 结果并不总是真实的。
- 无法紧跟时事。
- 难以应对复杂计算。
而Agent可以利用外部工具克服这些问题。LangChain则是提供一种通用的框架通过大语言模型的指令来轻松地实现这些工具的调用。
比如:
- Google搜索:获取最新信息
- Python REPL:执行代码
- Wolfram:进行复杂的计算
- 外部API:获取特定信息
{% note color:blue 提示%} Agent在本篇文章不会占太多篇幅,详细内容可以看文章底部参考资料 {% endnote %}
MCP
MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
对 Anthropic 可能没那么熟悉,但是 claude 一定听过,没错 Anthropic 就是 claude 的研发公司。
什么是MCP
这里给出官方的定义:
MCP(模型上下文协议)是一种用于将 AI 应用程序连接到外部系统的开源标准。使用 MCP,Claude 或 ChatGPT 等 AI 应用程序可以连接到数据源(例如本地文件、数据库)、工具(例如搜索引擎、计算器)和工作流程(例如专门的提示),从而使它们能够访问关键信息并执行任务。
可以将MCP视为人工智能应用的USB-C接口。正如USB-C提供了一种连接电子设备的标准化方式一样,MCP也提供了一种将人工智能应用连接到外部系统的标准化方式。
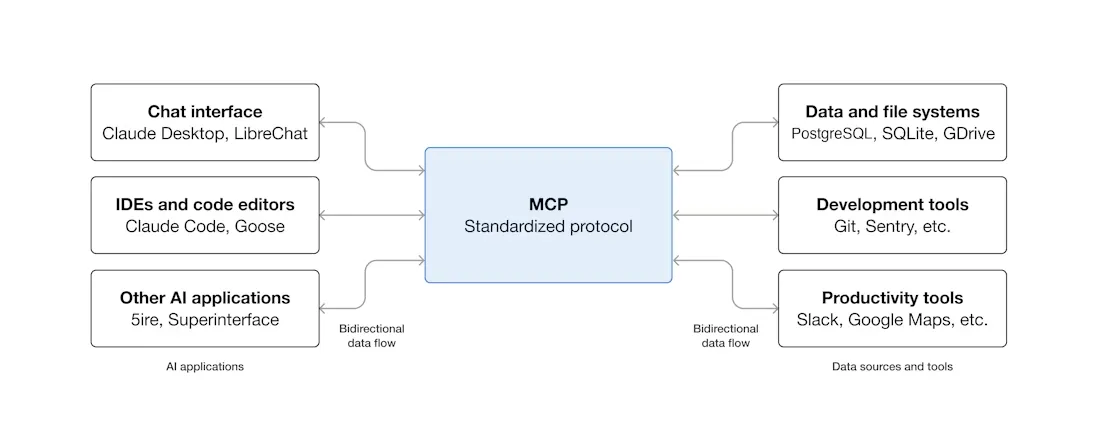
MCP可以做什么
- Agents 可以访问您的 Google 日历和 Notion,充当更加个性化的 AI 助手。
- Claude Code 可以使用 Figma 设计生成整个 Web 应用程序。
- 企业聊天机器人可以连接到组织内的多个数据库,使用户能够通过聊天分析数据。
- AI模型可以在Blender上创建3D设计,并使用3D打印机将其打印出来。
一句话概括,MCP “连接万物”
为什么MCP很重要?
根据你在生态系统中所处的位置,MCP 可以带来一系列好处。
- 开发者:MCP 可以减少构建 AI 应用程序或agent或与之集成时的开发时间和复杂性。
- AI 应用或代理:MCP 提供对数据源、工具和应用程序生态系统的访问,这将增强功能并改善最终用户体验。
- 最终用户:MCP 可实现功能更强大的 AI 应用程序或agent,这些应用程序或代理可以访问您的数据并在必要时代表您采取行动。
Function Calling是AI模型调用函数的机制,MCP是一个标准协议,使AI模型与API无缝交互,而AI Agent是一个自主运行的智能系统,利用Function Calling和MCP来分析和执行任务,实现特定目标。
即使是最强大模型也会受到数据隔离的限制,形成信息孤岛,要做出更强大的模型,每个新数据源都需要自己重新定制实现,使真正互联的系统难以扩展,存在很多的局限性。
现在,MCP 可以直接在 AI 与数据(包括本地数据和互联网数据)之间架起一座桥梁,通过 MCP 服务器和 MCP 客户端,大家只要都遵循这套协议,就能实现“万物互联”。
有了MCP,可以和数据和文件系统、开发工具、Web 和浏览器自动化、生产力和通信、各种社区生态能力全部集成,实现强大的协作工作能力,它的价值远不可估量。
对比MCP和Function Calling
Function Calling = 大模型调用「一个进程内的函数」的方式
MCP = 大模型与「外部世界服务 / 工具生态」通信的通用协议
换句话说:
- Function Calling 是一个 LLM 的“单机本地函数调用能力”
- MCP 是一个跨系统、跨进程、跨语言的“插件协议 + 远程工具系统”
| 维度 | Function Calling | MCP(Model Context Protocol) |
|---|---|---|
| 定位 | LLM 调用本地函数的机制 | 跨系统、跨语言的 AI 工具协议(插件系统) |
| 角色性质 | 调用方式 | 协议 + 工具生态体系 |
| 主要解决问题 | 大模型选择函数、结构化输出、避免幻觉 | 让模型能安全、标准化地访问外部工具 / 服务 |
| 工具所在位置 | 同一进程 / 同一代码库 | 本地或远程、独立服务、甚至多工具中心 |
| 通信方式 | 无通信,仅 JSON 输出 | 双向协议(WebSocket / STDIO) |
| 工具自动发现 | ❌ 不支持 | ✔️ 支持(工具可枚举、可描述) |
| 工具权限管理 | ❌ 不支持 | ✔️ 支持权限、会话管理 |
| 工具生命周期 | 无 | 工具可以有 session、状态管理 |
| 多 Agent 共享工具 | ❌ 不支持 | ✔️ 完全支持 |
| 多模型共享工具 | ❌ 不支持 | ✔️ 支持(GPT / Claude / Llama 都能用同一个 MCP 工具) |
| 多语言支持 | 工具必须使用宿主语言编写 | 工具独立于语言,只要遵守 MCP 协议即可 |
| 扩展性 | 一次性函数集合 | 插件式扩展(新增工具=新增一个 MCP Server) |
| 文件 / 流式支持 | ❌ 几乎没有 | ✔️ 支持文件操作、文件句柄、流式内容 |
| 典型场景 | API 服务、单应用、小规模工具调用 | 企业级 Agent、RAG 系统、自动化流程、跨系统编排 |
| 模型调用方式 | 由模型“选择函数 + 输出参数” | 模型按 MCP 协议与工具通信 |
| 返回值结构化 | ✔️ 强结构化 JSON | ✔️(JSON + 工具描述更强) |
| 能否用于构建插件生态 | ❌ 不能 | ✔️ 完整插件生态(类似 VSCode Extensions) |
| 远程服务调用 | ❌ 无内置支持,需要自己写网络层 | ✔️ 内置远程调用(协议层自带) |
| 复杂任务 orchestration | ❌ 靠开发者编写逻辑 | ✔️ 工具层 + Agent 可自动编排 |
| 是否是行业标准 | 不是标准,各厂商各用各的 | ✔️ 由 Anthropic 提出的规范,正成为统一标准 |
| 适合规模 | 小规模单体应用 | 大规模、多 Agent、企业级系统 |
工作原理
MCP 协议采用了一种独特的架构设计,它将 LLM 与资源之间的通信划分为三个主要部分:客户端、服务器和资源。
客户端负责发送请求给 MCP 服务器,服务器则将这些请求转发给相应的资源。这种分层的设计使得MCP 协议能够更好地控制访问权限,确保只有经过授权的用户才能访问特定的资源。
以下是 MCP 的基本工作流程:
- 初始化连接:客户端向服务器发送连接请求,建立通信通道。
- 发送请求:客户端根据需求构建请求消息,并发送给服务器。
- 处理请求:服务器接收到请求后,解析请求内容,执行相应的操作(如查询数据库、读取文件
- 等)。
- 返回结果:服务器将处理结果封装成响应消息,发送回客户端。
- 断开连接:任务完成后,客户端可以主动关闭连接或等待服务器超时关闭
通信机制
MCP 协议支持两种主要的通信机制:基于标准输入输出的本地通信和基于SSE(Server-Sent Events)的远程通信。
这两种机制都使用 JSON-RPC 2.0 格式进行消息传输,确保了通信的标准化和可扩展性。
本地通信 : 通过 stdio 传输数据,适用于在同一台机器上运行的客户端和服务器之间的通信。
远程通信 : 利用 SSE 与 HTTP 结合,实现跨网络的实时数据传输,适用于需要访问远程资源或分布式部署的场景。
FastMCP
什么是FastMCP
以下内容均来自FastMCP官方文档
构建 MCP 服务器和客户端的快速、Pythonic 方式。
FastMCP 是构建 MCP 应用程序的标准框架。模型上下文协议(MCP) 提供了一种将 LLM 连接到工具和数据的标准化方法,而 FastMCP 通过简洁的 Python 代码使其能够用于生产环境:
from fastmcp import FastMCP
mcp = FastMCP("Demo 🚀")
@mcp.tool
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
if __name__ == "__main__":
mcp.run()
FastMCP 开创了 Python MCP 开发的先河,FastMCP 1.0 于 2024 年被纳入官方 MCP SDK。
这是 FastMCP 2.0,一个积极维护的版本,其功能远超基本的协议实现。SDK 提供核心功能,而 FastMCP 2.0 则提供生产环境所需的一切:高级 MCP 模式(服务器组合、代理、OpenAPI/FastAPI 生成、工具转换)、企业级身份验证(Google、GitHub、Azure、Auth0、WorkOS 等)、部署工具、测试框架和全面的客户端库。
代码实现
使用一个简单案例对FastMCP快速入门
依赖安装
pip install fastmcp
服务端
mcp_server.py
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
@mcp.tool
def greet(name: str) -> str:
return f"Hello, {name}!"
if __name__ == "__main__":
mcp.run()
运行
方式一:
python mcp_server.py
这种方式要求代码中有 if __name__ == "__main__" 代码块,对此,官方的解释是:
{% note color:green 说明%}
我们为什么需要这个if __name__ == "__main__":模块?为了保持一致性和兼容性,建议添加此__main__代码块,以确保您的服务器能够与所有将服务器文件作为脚本执行的 MCP 客户端兼容。如果用户仅使用 FastMCP CLI 运行服务器,则可以省略此代码块,因为 CLI 会直接导入服务器对象。
{% endnote %}
方式二:
使用默认 stdio 传输方式运行此服务器
fastmcp run my_server.py:mcp
方式三:
使用 HTTP 传输协议运行此服务器
fastmcp run my_server.py:mcp --transport http --port 8000
我们使用方式三,执行后控制台会有以下输出表示成功:
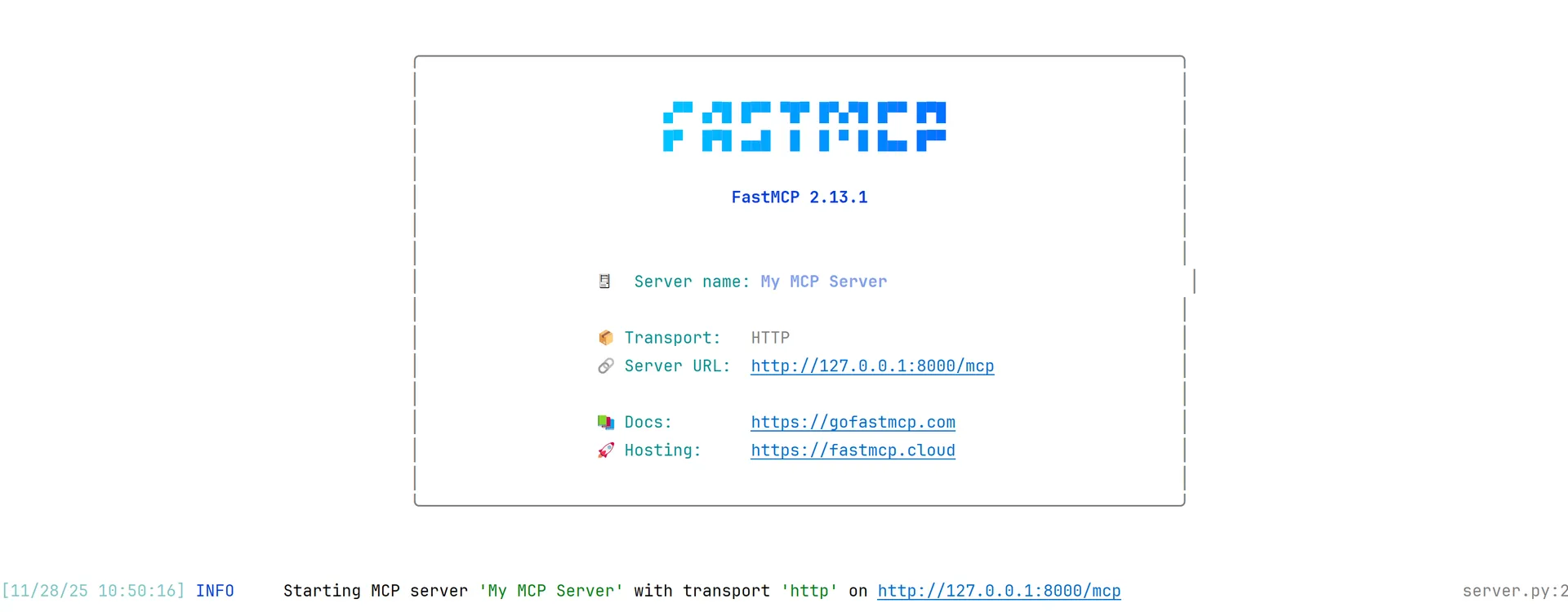
客户端
mcp_client.py
import asyncio
from fastmcp import Client
client = Client("http://localhost:8000/mcp")
async def call_tool(name: str):
async with client:
result = await client.call_tool("greet", {"name": name})
print(result)
asyncio.run(call_tool("Ford"))
输出:
CallToolResult(content=[TextContent(type='text', text='Hello, Ford!', annotations=None, meta=None)], structured_content={'result': 'Hello, Ford!'}, meta=None, data='Hello, Ford!', is_error=False)
是一个 CallToolResult 对象,可以从中拿到自己所需的属性。
End
ok,文章到这里就结束了,MCP是24年年底才发布的,相对来说还是比较新的东西,但是很多已经在工程化项目中用上了,技术发展确实是快啊。