注意力机制的数学基础与KV Cache的本质
标准注意力机制的数学表达
标准的多头注意力(MHA)可形式化定义为:
给定输入序列$X \in \mathbb{R}^{L \times d{model}}$,其中$L$为序列长度,$d{model}$为隐藏层维度。对于第$i$个头:
注意力输出:
KV Cache是什么
在 Transformer 中,Attention 会为每个 Token 计算:
- Q(Query)
- K(Key)
- V(Value)
在推理(inference)阶段,模型是 自回归地产生下一个 token: 每次只输入最新的 token,但需要与 所有历史 token 的 K 和 V 进行注意力计算。
但是在token by token递归生成时,新预测出来的第t+1个token,并不会影响到已经算好的k、v,因此这部分结果我们可以缓存下来供后续生成调用,避免不必要的重复计算,这就是所谓的KV Cache。
{% note color:green (‾◡◝) %} 传统MHA的KV Cache存在一个问题,KV cache的存在,本来是为了避免在推理阶段对前置序列的重复计算的。但是,随着前置序列的长度变长(我们记为kv_len),需要读取的KV cache也将越来越大,数据的传输成本增加,这就使得attn计算逐渐变成memory bound,所以,降低KV cache大小极为重要 {% endnote %}
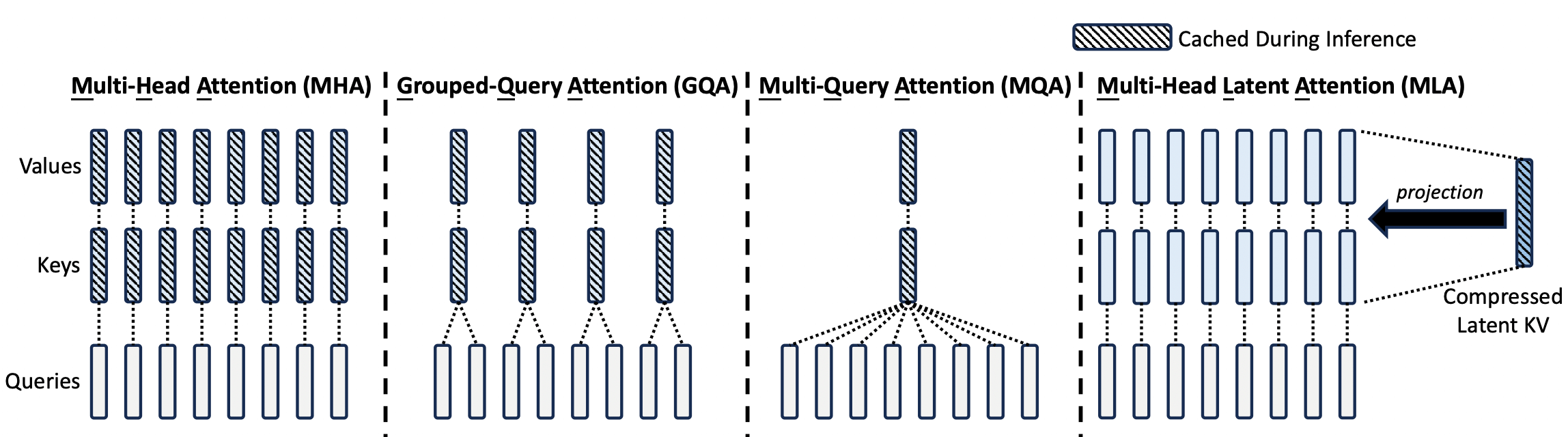
MQA
Multi-Query Attention,首次提出在《Fast Transformer Decoding: One Write-Head is All You Need》
MQA的数学定义
MQA的核心创新在于共享KV投影矩阵:
每个头使用相同的$K$和$V$,但保持不同的$Q_i$投影。
内存复杂度分析
假设有$h$个头,序列长度$L$,维度$dk = dv = d_{model}/h$:
- MHA KV Cache大小:$2 \times h \times L \times dk = 2Ld{model}$
- MQA KV Cache大小:$2 \times L \times dk = \frac{2Ld{model}}{h}$
表达能力
原本对于每个token,每个head都有各自的k、v,保存不同的信息,MQA将其压缩为一份,首先,肯定会影响表达能力,造成模型效果缺失,不过,并不一定每个head的信息都是有用的,压缩后也可能会丢掉冗余信息,这也是模型内部的不确定性。
对于效果上的损失,可以通过进一步训练来弥补,还可以增加FFN规模,对于显存节省方面,MQA的效果可以说非常可观了。
使用MQA的模型包括PaLM、StarCoder、Gemini等。
GQA
有人担心MQA对KV cache压缩太严重,影响模型最终效果,所以,作为一种折中方案,GQA(Grouped-Query Attention)出现了
《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》 发表在2023年5月
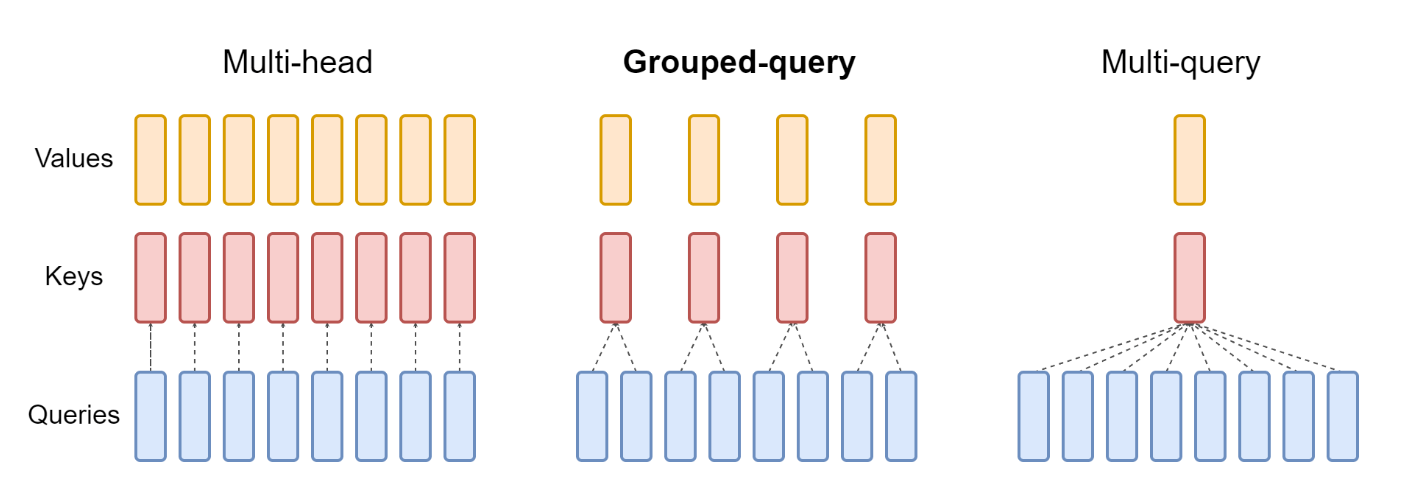
GQA数学形式
将$h$个头分为$g$组,每组有$m = h/g$个头共享KV投影:
分析
GQA提供了MHA到MQA的自然过渡,当$g=h$时就是MHA,$g=1$时就是MQA,当$1<g<h$时,它只将KV Cache压缩到$g/h$,压缩率不如MQA,但同时也提供了更大的自由度,效果上更有保证。
GQA最知名的使用者,大概是Meta开源的LLAMA2-70B,以及LLAMA3全系列,此外使用GQA的模型还有TigerBot、DeepSeek-V1、StarCoder2、Yi、ChatGLM2、ChatGLM3等,相比使用MQA的模型更多(ChatGLM虽然在它的介绍中说自己是MQA,但实际是g=2的GQA)。
在llama2/3-70B中,GQA的g=8,其他用了GQA的同体量模型基本上也保持了这个设置,这并非偶然,而是同样出于推理效率的考虑。我们知道,70B这个体量的模型,如果不进行极端的量化,那么不可能部署到单卡(A100/H100 80G)上。单卡不行,那么就能单机了,一般情况下一台机可以装8张卡,刚才我们说了,Attention的每个Head实际上是独立运算然后拼接起来的,当g=8时,正好可以每张卡负责计算一组K、V对应的Attention Head,这样可以在尽可能保证K、V多样性的同时最大程度上减少卡间通信。
MLA
Multi-head Latent Attention
{% note 对于一个token,为什么要保存所有head上的K值作为K cache(V cache也是同理)?→ 因为每个khead都附带不同的信息,它将用这份独有的信息和对应的qhead进行attn的计算,即$attn_weights = (W{Q}h{i})^{T} * (W{K}h{j})$,这里的$W{Q}, W{K}$是合并了所有head对应的param weight后的表达。 %}
这里只对MLA的思想进行分析,数学推导以及矩阵形状变换不做拆解,笔者能力有限
MLA的核心在于用更低维的latent空间来存 KV,不再直接存储高维 K 和 V。