传统 Attention 的瓶颈
要理解 Flash Attention,首先要明白标准 Transformer 中 Self-Attention 的计算和内存瓶颈。
{% note color:yellow 先验知识 %}
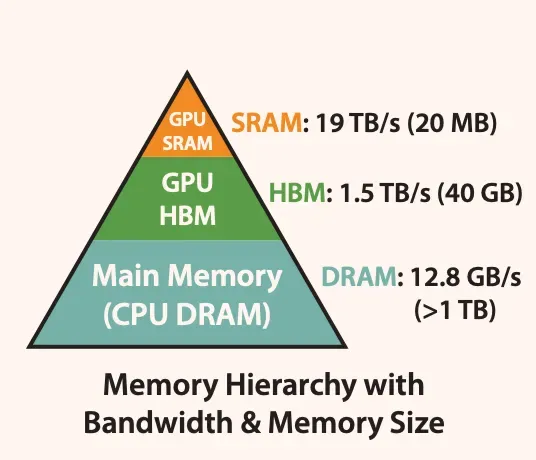
HBM(High Bandwidth Memory)和SRAM(Static Random-Access Memory)
- HBM是一种高带宽内存接口,用于3D堆叠的SDRAM,具有较高的带宽和较低的功耗。
- SRAM是一种静态随机访问存储器,用于高速缓存等内部存储器,具有更快的访问速度和更低的延迟,但成本更高且占用更多芯片空间。
MAC
- MAC(Memory Access Cost,存储访问开销)是指在计算机系统中,访问内存或存储器所需的时间和资源开销。它是衡量计算机程序或算法性能的重要指标之一。 MAC的值取决于多个因素,包括内存层次结构、缓存命中率、内存带宽、存储器延迟等。较低的MAC值表示访问内存的开销较小,而较高的MAC值表示访问内存的开销较大。
{% endnote %}
标准 Attention 的计算过程回顾
对于一个输入序列,经过线性变换得到 Q, K, V 矩阵。核心的 Attention 计算步骤:
- S = QKᵀ (计算相似度得分矩阵,维度:[序列长度 N, 序列长度 N])
- P = softmax(S / √dₖ)
- O = PV (加权求和,得到输出矩阵 O)
核心瓶颈
中间显存爆炸 (Memory-Bound)
这是最关键的问题。注意 S 和 P 的大小是 N²。
- 当 N 很大时(例如长文本、高分辨率图像),这个矩阵会变得极其巨大。
- 举例:N=1000, 数据类型 float32,仅 S 矩阵就需要
1000 * 1000 * 4 Bytes ≈ 4GB的显存。N=16000 时,需要约 1TB 显存!这直接限制了模型可处理的序列长度。
传统实现会:
- 把 QKᵀ 写到显存
- softmax 时又读回来
- 再写结果
- 再读结果做与 V 的乘法
- …循环反复
导致:
- 显存 IO 占主导
- 序列越长(例如几千几万 token),越慢、越吃显存
Attention 不是算力瓶颈,而是 IO 瓶颈。
这就是 FlashAttention 要解决的核心问题。
FlashAttention
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
快速计算 节省内存 确切注意力
核心思想
Flash Attention 的核心思想是一种 算法重排。它通过 “分块计算” 和 “增量更新” 的技术,在不显式生成和存储完整 S 和 P 矩阵的情况下,直接计算出正确的输出 O。
其目标非常明确:
- 减少对 HBM 的访问次数(从 O(N²) 降到 O(N) 级别),让计算不再受限于内存带宽。
- 避免存储中间矩阵,从而支持超长序列。
采用的方法:
- tiling
- recomputation
tiling(分块)
注意,attention的计算涉及到softmax,不能简单分块
传统softmax计算方法:
softmax操作是row-wise的,即每行都算一次softmax,所以需要用到平铺算法来分块计算softmax。
【safe softmax】 原始softmax数值不稳定,为了数值稳定性,FlashAttention采用safe softmax,向量 ∈ R 的safe softmax 计算如下:
,$f(x) := \begin{bmatrix} e^{x1 - m(x)} & \cdots & e^{xB - m(x)} \end{bmatrix}\quad \ell(x) := \sumi f(x)i\tag{3}$
Flash Attention中的softmax可以看做online softmax
它维护两个额外的统计量,并允许我们 增量更新 这些统计量和输出。 假设我们把输入向量 x 分成两部分处理:$x = [x^{(1)}, x^{(2)}]$。
当看到第一部分 时:
- 计算本地统计量:$m1 = \max(x^{(1)})$, $\ell1 = \sum e^{x^{(1)} - m_1}$。
- 此时的最佳估计输出:$o1 = \frac{e^{x^{(1)} - m1}}{\ell_1}$。
当看到第二部分 时:
- 计算本地统计量:$m2 = \max(x^{(2)})$, $\ell2 = \sum e^{x^{(2)} - m_2}$。
- 关键步骤:更新全局统计量
- 新的全局最大值:$m{\text{new}} = \max(m1, m_2)$
- 新的全局指数和:
- 对于旧的 ,它的指数是用旧的 计算的,现在需要用新的 来"修正"。
- 修正因子是 。
- 因此,旧的 需要缩放为 。
- 新的 也需要用新最大值修正为 。
- 最终全局 。
- 更新输出
- 修正旧的 :$o1 = o1 \cdot e^{m1 - m{\text{new}}}$ (因为分母 变了,分子也需要同步缩放)。
- 计算新的 :$o2 = \frac{e^{x^{(2)} - m{\text{new}}}}{\ell_{\text{new}}}$。
- 最终输出:$o = \text{concat}(o1, o2)$
softmax分块计算完整公式推导:
\ell(x) = \ell(\begin{bmatrix} x^{(1)} & x^{(2)} \end{bmatrix}) = e^{m(x^{(1)}) - m(x)} \ell(x^{(1)}) + e^{m(x^{(2)}) - m(x)} \ell(x^{(2)}), \tag{4}
recomputation(重新计算)
FlashAttention算法的目标:在计算中减少显存占用,从 大小降低到线性,这样就可以把数据加载到SRAM中,提高IO速度。
解决方案:传统Attention在计算中需要用到Q,K,V去计算S,P两个矩阵,FlashAttention引入softmax中的统计量 ,结合output O和在SRAM中的Q,K,V块进行计算。
具体实现:
反向传播需要什么? 对于标准 Attention:$O = \text{softmax}(QK^\top / \sqrt{d}) V$,反向传播需要计算损失 对 的梯度。 根据链式法则:
(需要注意力矩阵 )
(需要 )
(需要 和 ,其中 是 softmax 的局部梯度,计算它需要 或 )
结论:要计算对 的梯度,至少需要 或 矩阵。 而我们在前向传播中恰恰没有存储它们。
Flash Attention 的解决方案:从输出反推中间值 既然前向没有存 和 ,那就在反向传播需要的时候,当场重新算一遍。
但这带来了新的挑战:重算 仍然是 的 HBM 访问和计算,会拖慢反向传播。
Flash Attention 的精妙之处在于,它利用了前向传播已经计算并存储下来的少量信息,使得重计算变得高效。这些信息就是:
- 最终的输出
- 每行(每个查询位置)的 softmax 统计量:$m$(最大值) 和 (指数和)
重计算的过程(反向传播的双循环): 反向传播的数据流与前向传播完全镜像,也是一个外循环遍历 块,内循环遍历 块。
当需要计算某个 块和 块相关的梯度时:
- 重新加载 块到 SRAM(这些是输入,HBM 中一直有)。
- 在 SRAM 中重算该分块的注意力分数 。
- 利用存储的统计量 和 快速重算该分块的注意力概率矩阵 :
- 对于 的每一行 ,对应的 是该行的全局最大值,$l_i$ 是该行的全局指数和。
- 可以直接计算出正确的行归一化因子:$P{ij}^{(\text{row})} = \frac{e^{s - mi}}{l_i}$。
- 注意:这里不需要再做一次完整的 Online Softmax,因为全局统计量 和 已知。这只是一个快速的逐元素指数和除法操作。
- 现在,我们在 SRAM 中有了 。
- 结合从上游传递过来的梯度 (也分块加载),我们就可以在 SRAM 中本地计算出对 分块的梯度 。
- 对这些局部梯度进行累加(例如,$\frac{dL}{dQi}$ 由所有 对应的 $\frac{dL}{dQ{ij}}$ 累加而成),最终得到完整的梯度。